DNNDK: AI Edge Platform on ZynQ FPGA
Introduction
DNNDK allows the productivity in deploying AI inference on Xilinx platforms. In fact, it provides a solution for deep neural network applications. So, in this article we will present the DNNDK tool for the FPGA integration of Deep Neural Network and Convolutional Neural Network.
Artificial Neural Networks
Artificial neural networks (ANN) or connectionist systems are computing systems similar to biological neural networks likes animal brains. In particular, such systems "learn" to perform tasks by considering examples, generally without being programmed with task-specific rules. At this point, you can get it to learn things, recognize patterns, and make decisions in a "human-like" way.
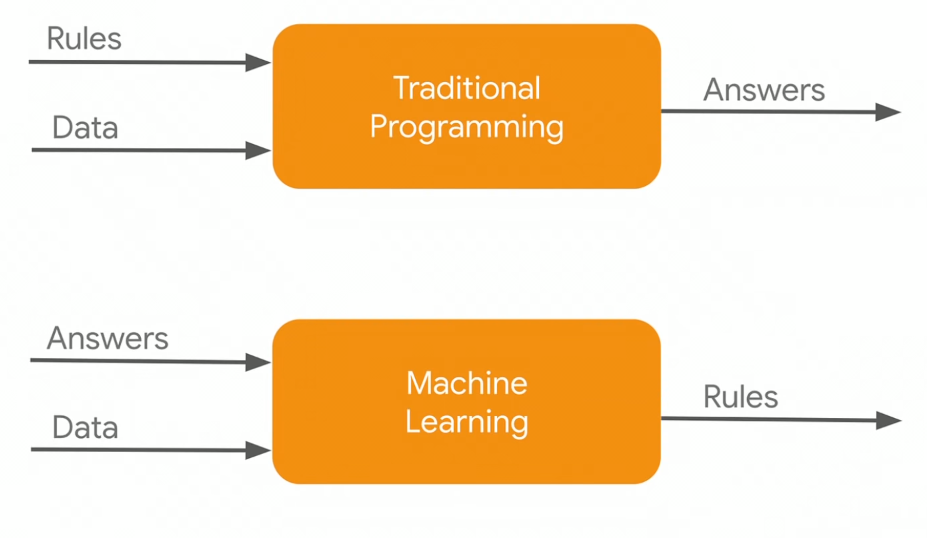
Traditional programming vs Machine Learning (Laurence Moroney and Karmel Allison)
How does a neural network learn?
Information flows through a neural network in two different ways. When the model is learning (being trained) or operating normally (after being trained either being used or tested), patterns of information from the dataset are being fed into the network via the input neurons, which trigger the layers of hidden neurons, and these, in turn, arrive at the output neurons (called a feedforward network). Moreover, not all neurons “fire” all the time. In fact, each neuron receives inputs from the neurons to its left, and the inputs are multiplied by the weights of the connections they travel along. Also, every neuron adds up all the inputs it receives in this way and (this is the simplest neural network) if the sum is more than a certain threshold value, the neuron “fires” and triggers the neurons it’s connected to (the neurons on its right).
In other words, a possible definition of Deep Learning is:
Deep Learning refers to neural networks with multiple hidden layers that can learn increasingly
abstract representation of the input data.
DNNDK™ (Deep Neural Network Development Kit)
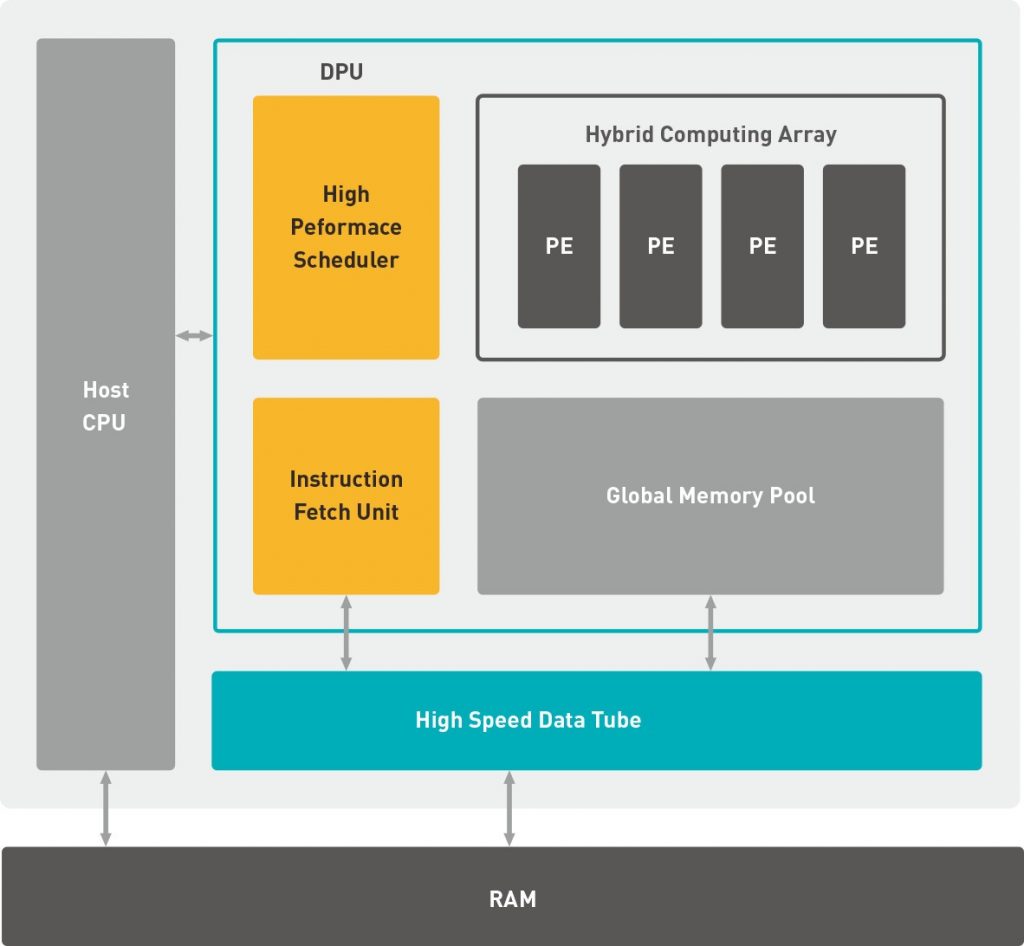
DNNDK allows the productivity and efficiency of deploying AI inference on Xilinx Edge AI platforms.
In particular it provides a unified solution for deep neural network inference applications by providing pruning, quantization, compilation, optimization, and runtime support.
DNNDK consists of:
- DEep ComprEssioN Tool (DECENT)
- Then Deep Neural Network Compiler (DNNC)
- Finally Neural Network Runtime (N2Cube)
DNNDK features
So, the most important feature of DNNDK v3.0 is that popular deep learning framework TensorFlow is officially supported by DNNDK toolchain; also TensorFlow framework is supported by DECENT. Finally, Caffe and TensorFlow are supported by one single DNNC binary tool.
The evaluation boards supported for this framework (at version 3.1) are:
- Xilinx® ZCU102
- Xilinx ZCU104
- Avnet Ultra96

In particular, the performances on these boards are very impressive, taking a look at a ZCU104 (performances reported here: https://github.com/Xilinx/AI-Model-Zoo ):
| Model | E2E latency (ms) Thread num=1 |
E2E throughput (fps) (Single Thread) |
E2E throughput (fps) (Multi-Thread) |
| resnet50 | 12.13 | 82.45 | 151.8 |
| Inception_v1 | 5.07 | 197.333 | 404.933 |
| Inception_v2 | 6.33 | 158.033 | 310.15 |
| Inception_v3 | 16.03 | 62.3667 | 126.283 |
| mobileNet_v2 | 3.85 | 259.833 | 536.95 |
| tf_resnet50 | 11.31 | 88.45 | 163.65 |
| tf_inception_v1 | 6.35 | 157.367 | 305.467 |
| tf_mobilenet_v2 | 5.21 | 191.867 | 380.933 |
| ssd_adas_pruned_0.95 | 10.69 | 93.5333 | 242.917 |
| ssd_pedestrain_pruned_0.97 | 12.13 | 82.45 | 236.083 |
| ssd_traffic_pruned_0.9 | 16.48 | 60.6667 | 159.617 |
| ssd_mobilnet_v2 | 37.78 | 26.4667 | 116.433 |
| tf_ssd_voc | 75.09 | 13.3167 | 33.5667 |
| densebox_320_320 | 2.33 | 428.533 | 1167.35 |
| densebox_360_640 | 4.65 | 215.017 | 626.317 |
| yolov3_adas_prune_0.9 | 10.51 | 95.1667 | 228.383 |
| yolov3_voc | 66.37 | 15.0667 | 33 |
| tf_yolov3_voc | 66.74 | 14.9833 | 32.8 |
| refinedet_pruned_0.8 | 28 | 35.7167 | 79.1333 |
| refinedet_pruned_0.92 | 14.54 | 68.7833 | 160.6 |
| refinedet_pruned_0.96 | 10.39 | 96.2333 | 241.783 |
| FPN | 15.72 | 63.6167 | 177.333 |
| VPGnet_pruned_0.99 | 8.91 | 112.233 | 355.717 |
| SP-net | 1.6 | 626.5 | 1337.33 |
| Openpose_pruned_0.3 | 267.86 | 3.73333 | 12.1333 |
| yolov2_voc | 37.66 | 26.55 | 63.7833 |
| yolov2_voc_pruned_0.66 | 17.51 | 57.1167 | 158.917 |
| yolov2_voc_pruned_0.71 | 15.63 | 63.9667 | 186.867 |
| yolov2_voc_pruned_0.77 | 13.78 | 72.55 | 224.883 |
| Inception-v4 | 32.33 | 30.9333 | 64.6 |
| SqueezeNet | 3.52 | 284.033 | 940.917 |
| face_landmark | 1.02 | 977.683 | 1428.2 |
| reid | 2.45 | 407.583 | 702.717 |
| yolov3_bdd | 69.77 | 14.3333 | 31.7 |
| tf_mobilenet_v1 | 3.03 | 330.25 | 728.35 |
| resnet18 | 4.84 | 206.65 | 428.55 |
| resnet18_wide | 31.23 | 32.0167 | 62.7667 |
Key Features
Firstly it provides a complete set of toolchains with compression, compilation, deployment, and profiling.
Secondly it supports mainstream frameworks and the latest models capable of diverse deep learning tasks
Moreover it provides a lightweight standard C/C++ programming API (no RTL programming knowledge required)
Furthermore scalable board support from cost-optimized to performance-driven platforms
Finally supports system integration with both SDSoC and Vivado
DNNDK Framework
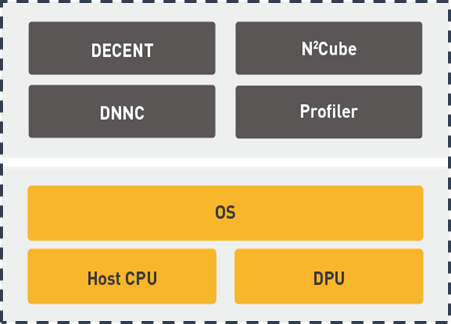
DNNDK is composed by different parts.
DECENT
Firstly, the process of inference is computation-intensive and requires a high memory bandwidth to satisfy the low latency and high throughput requirement of edge applications. Furthermore, the Deep Compression Tool, DECENT, employs coarse-grained pruning, trained quantization and weight sharing to address these issues while achieving high performance and high energy efficiency with very small accuracy degradation.
DNNC
Secondly, DNNC™ (Deep Neural Network Compiler) is the dedicated proprietary compiler designed for the DPU. In fact, it maps the neural network algorithm to the DPU instructions to achieve maxim utilization of DPU resources by balancing computing workload and memory access.
DNNAS
Thirdly, the Deep Neural Network Assembler (DNNAS) is responsible for assembling DPU instructions into ELF binary code. So, DNNC code generating backend cannot be invoked alone.
Profiler
Moreover, the DPU profiler is composed of two components: DPU tracer and DSight. DPU tracer is implemented in the DNNDK runtime N2 cube, and it is responsible for gathering the raw profiling data while running neural networks on DPU. On the other hand, with the provided raw profiling data, DSight can help to generate the visualized charts for performance analysis.
N2Cube
Finally, the Cube of Neutral Networks (N2Cube) is the DPU runtime engine. In particular, it acts as the loader for the DNNDK applications and handles resource allocation and DPU scheduling. In addition to this, its core components include DPU driver, DPU loader, tracer, and programming APIs for application development.
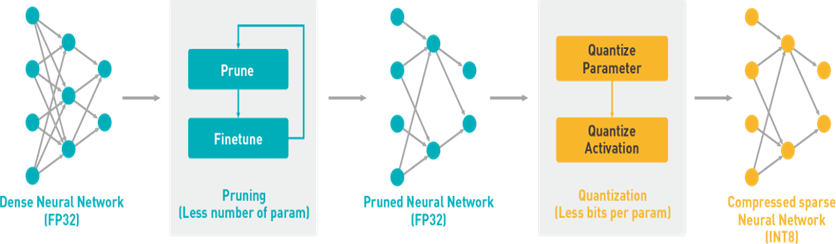
Network Deployment Overview
There are two stages for developing deep learning applications: training and inference.
Specifically, the DNNDK toolchain provides an innovative workflow to efficiently deploy deep learning inference applications on the DPU with five simple steps:
- Compress the neural network model;
- Compile the neural network model;
- Program with DNNDK APIs;
- Compile the hybrid DPU application;
- Run the hybrid DPU executable;
- Programming with DNNDK.
To develop deep learning applications on the DPU, three types of work must be done:
- Use DNNDK APIs to manage DPU kernels;
- DPU kernel creation and destruction;
- DPU task creation;
- Managing input and output tensors;
- Implement kernels not supported by the DPU on the CPU;
- Add pre-processing and post-processing routines to read in data or calculate results.
Conclusions
To conclude, we have presented the DNNDK tool for the FPGA integration of Deep Neural Network and Convolutional Neural Network. Finally, if you need more information about this tool or if you need support or consultancy, please send us a mail at
staff@www.makarenalabs.com

Could you please share the performance data of ZCU102 and Ultra96 on Xilinx Model-Zoo with me?I want to choose which board to use in my program.
Hi, thanks for your interest. What kind of performance data do you need? ZCU102 and Ultra96 are very different according to speed and power consumption.
If you need only performances about latency for the neural networks, you can visit the Vitis Model Zoo repository (https://github.com/Xilinx/Vitis-AI/tree/master/models/AI-Model-Zoo)